-
Azure AI Form Recognizer를 활용한 영어단어장 만들기AI&ML 2023. 2. 9. 21:42반응형
안녕하세요. 요즘 매일매일 눈을뜨면 새로운 AI서비스들을 테크기업들이 경쟁적으로 내놓고 있습니다.
기계학습을 해서 내가 직접 커스텀한 모델을 생성할수도 있지만, 실제 생활에 적용되는 모델을 만들려면, 많은 양의 양질의 데이터가 있어야합니다. 그래서, 많은 기업들이 대량의 데이터를 활용하여 이미 좋은 모델들을 오픈하고 있습니다.
오늘은 그중에 하나인 Azure AI 서비스중에 하나인 Form Recognizer 를 이용해서 PDF 문서나 이미지에서 글자를 추출하는 서비스를 만들어 볼게요.
Azure Portal에서 Cognitive Services 를 생성하고, 미리 빌드된 여러 AI서비스중에 Form Recognizer를 선택하고, Form Recognizer 스튜디오를 열면, 아래와 같이 샘플이 나오고 문서나 이미지를 업로드하면, 텍스트를 인식하여 결과 값으로 Json 형태로 반환하는 것을 보여줍니다. Code 탭을 선택하면, 자바스크립트,파이썬,C# 중에 하나를 선택할수 있습니다.
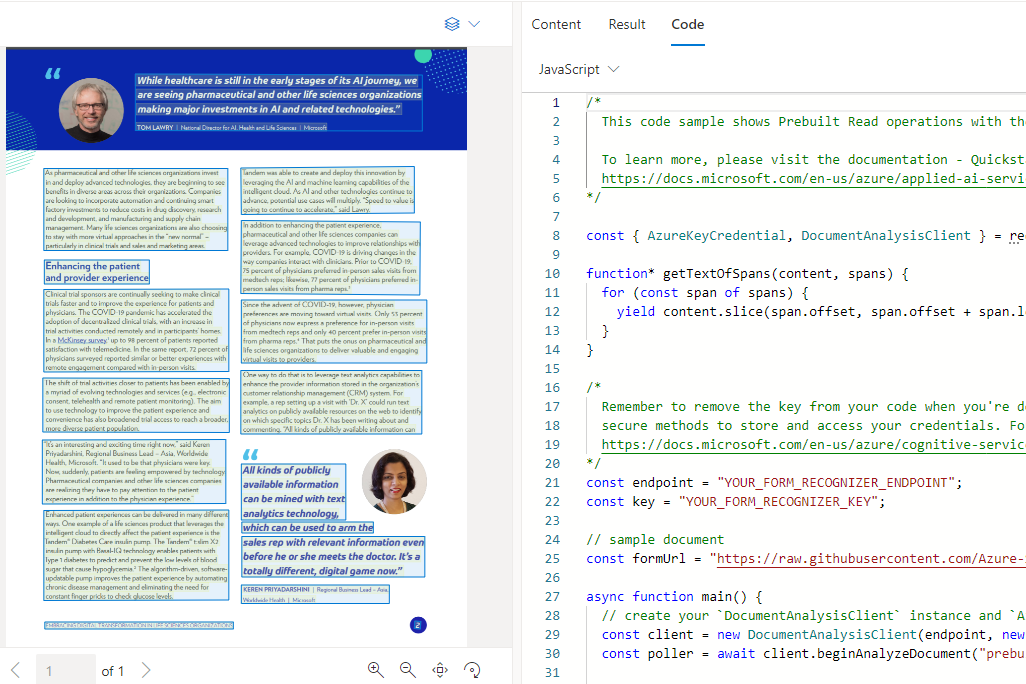
자바스크립트를 선택하면 아래와 같이 활용가능한 샘플코드가 나옵니다.
/* This code sample shows Prebuilt Read operations with the Azure Form Recognizer client library. To learn more, please visit the documentation - Quickstart: Form Recognizer Javascript client library SDKs https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/quickstarts/try-v3-javascript-sdk */ const { AzureKeyCredential, DocumentAnalysisClient } = require("@azure/ai-form-recognizer"); function* getTextOfSpans(content, spans) { for (const span of spans) { yield content.slice(span.offset, span.offset + span.length); } } /* Remember to remove the key from your code when you're done, and never post it publicly. For production, use secure methods to store and access your credentials. For more information, see https://docs.microsoft.com/en-us/azure/cognitive-services/cognitive-services-security?tabs=command-line%2Ccsharp#environment-variables-and-application-configuration */ const endpoint = "YOUR_FORM_RECOGNIZER_ENDPOINT"; const key = "YOUR_FORM_RECOGNIZER_KEY"; // sample document const formUrl = "https://raw.githubusercontent.com/Azure-Samples/cognitive-services-REST-api-samples/master/curl/form-recognizer/rest-api/read.png" async function main() { // create your `DocumentAnalysisClient` instance and `AzureKeyCredential` variable const client = new DocumentAnalysisClient(endpoint, new AzureKeyCredential(key)); const poller = await client.beginAnalyzeDocument("prebuilt-read", formUrl); const { content, pages, languages, styles } = await poller.pollUntilDone(); if (pages.length <= 0) { console.log("No pages were extracted from the document."); } else { console.log("Pages:"); for (const page of pages) { console.log("- Page", page.pageNumber, `(unit: ${page.unit})`); console.log(` ${page.width}x${page.height}, angle: ${page.angle}`); console.log(` ${page.lines.length} lines, ${page.words.length} words`); if (page.lines.length > 0) { console.log(" Lines:"); for (const line of page.lines) { console.log(` - "${line.content}"`); // The words of the line can also be iterated independently. The words are computed based on their // corresponding spans. for (const word of line.words()) { console.log(` - "${word.content}"`); } } } } } if (languages.length <= 0) { console.log("No language spans were extracted from the document."); } else { console.log("Languages:"); for (const languageEntry of languages) { console.log( `- Found language: ${languageEntry.languageCode} (confidence: ${languageEntry.confidence})` ); for (const text of getTextOfSpans(content, languageEntry.spans)) { const escapedText = text.replace(/\r?\n/g, "\\n").replace(/"/g, '\\"'); console.log(` - "${escapedText}"`); } } } if (styles.length <= 0) { console.log("No text styles were extracted from the document."); } else { console.log("Styles:"); for (const style of styles) { console.log( `- Handwritten: ${style.isHandwritten ? "yes" : "no"} (confidence=${style.confidence})` ); for (const word of getTextOfSpans(content, style.spans)) { console.log(` - "${word}"`); } } } } main().catch((error) => { console.error("An error occurred:", error); process.exit(1); });이 코드를 이용하여 API를 먼저 만듭니다.
저는 express 를 이용해서 파일을 업로드 받는 서비스와 이 파일을 위에서 보여드린 Form Recognizer API 서비스를 이용하여 글자값을 받아서 화면에 뿌려주는것을 만들어 보았습니다.

간단하게 이미지를 텍스트로 바꾸는 서비스를 만들었고, 클라이언트는 간단한 React 로 만들어서 아래처럼 파일을 업로드 받게 만들었습니다.
디자인은 자신이 없기에..리액트 부트스트랩을 이용하였습니다.

영어 문제지에 있는 내용을 찍어서 파일을 업로드합니다. 조금 지나면, 아래처럼 텍스트로 변환된 값을 반환 받고, 단어만 추출해서 리스트로 뿌려주었습니다.
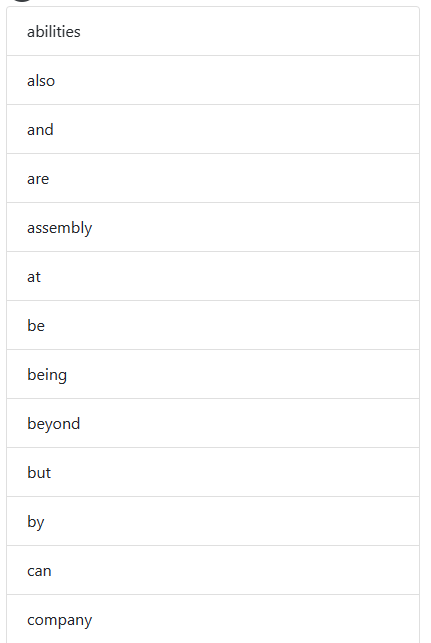
간단하지만, 멋진 단어장이 됬네요.^^ pre-build 된 모델을 사용하여 여러 가지 애플리케이션에 활용 가능할것 같습니다. 아이들을 위해서 단어장을 만들어주고 테스트도 할수 있게 만들어주고 싶네요.^^
반응형'AI&ML' 카테고리의 다른 글
나의 TXT 데이터를 OpenAI를 이용하여 FastAPI로 서비스해보자! (0) 2023.05.03 챗GPT 생성AI의 시대 - 기본개념 이해하기 (0) 2023.04.15 Github Actions을 이용한 간단한 Docker 빌드/배포 자동화 (0) 2023.02.07 Hugging Face 로 AI 모델 맛보기!! (0) 2023.02.05 초간단한 AI모델 만들기(구글Colab)-Iris.csv (0) 2023.02.02