-
나의 TXT 데이터를 OpenAI를 이용하여 FastAPI로 서비스해보자!AI&ML 2023. 5. 3. 00:10반응형
안녕하세요. LLM 모델인 chat gpt 를 활용해서 나만의 텍스트 데이터를 OpenAI를 연동해서 질문해 보는 서비스를 만들어 보겠습니다. 간단하게 파이썬을 이용해서 아래와 같은 순서로 작업합니다.
필요한 라이브러리를 설치해줍니다.
openai 같은 LLM 모델들을 이용해서 애플리케이션을 개발하는데 유용한 Langchain 라이브러리를 이용합니다.
from fastapi import FastAPI ,File, UploadFile , Request from pydantic import BaseModel from langchain.document_loaders import DirectoryLoader, TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chains import RetrievalQA from langchain.llms import AzureOpenAI from langchain.prompts import PromptTemplate from dotenv import load_dotenv from fastapi.responses import HTMLResponse from fastapi.templating import Jinja2Templates import os import openai이 코드는 Python 언어로 작성된 FastAPI 웹 애플리케이션입니다. 다양한 라이브러리와 패키지를 import하고, FastAPI를 생성합니다. 이 웹 애플리케이션은 파일 업로드, 요청 처리 등의 기능을 수행하며, langchain, pydantic, dotenv, openai 등의 라이브러리를 사용합니다. Jinja2Templates를 사용하여 HTMLResponse를 반환하며, AzureOpenAI, RetrievalQA, PromptTemplate 등 다양한 기능을 수행합니다. 코드 상단에는 .env 파일을 로드하는 코드도 있습니다.
Azure OpenAI 설정들을 환경파일에서 읽어옵니다.
openai.api_type = "azure"
openai.api_version = "2022-12-01"
openai.api_base = os.getenv('OPENAI_API_BASE')
openai.api_key = os.getenv("OPENAI_API_KEY")아래 함수는 RetrievalQA 인스턴스를 생성하는 함수입니다. 이 함수는 AzureOpenAI를 사용하여 생성한 Language Model, OpenAIEmbeddings를 사용하여 텍스트 문서의 임베딩을 만들고, DirectoryLoader를 사용하여 텍스트 문서를 로드합니다. 그런 다음 CharacterTextSplitter를 사용하여 텍스트 문서를 chunk로 분할하고, Chroma를 사용하여 vector store를 생성합니다.
def create_qa() -> RetrievalQA: # Create a language model for Q&A llm = AzureOpenAI(deployment_name="text-davinci-003") # Create embeddings for text documents embeddings = OpenAIEmbeddings(model="text-embedding-ada-002", chunk_size=1) # Load text documents loader = DirectoryLoader('mydata', glob="**/*.txt") documents = loader.load() # Split text documents into chunks 중지 시퀀스 text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=50) texts = text_splitter.split_documents(documents) # Create a vector store for text documents docsearch = Chroma.from_documents(texts, embeddings) # Create a retrieval-based Q&A system qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 1})) return qa아래 서비스는 POST 방식의 "/qna/" 경로를 가진 endpoint를 정의하는 함수입니다. 이 함수는 Question 모델을 받아들이고, 이전에 만든 RetrievalQA 인스턴스인 qa_global을 사용하여 입력된 질문에 대한 답변을 찾습니다. 마지막으로, 답변을 JSON 형식으로 반환하고 이 답변을 웹에 보여줍니다.
@app.post("/qna/") def get_qna(question: Question): # qa = qa_global answer = qa_global.run(question.question) return {"data": answer}간단하게 Fast API를 이용해서 서비스를 만들고, 데이터를 벡터 데이터베이스인 chroma db에 저장해서 쿼리시 답변을 조회합니다.
실행하면 아래와 같이 OpenAI와 활용할 나의 텍스트 파일을 업로드 합니다.

아래 질문란에 llm 모델이 어떻게 동작하는지 질문해 보았습니다.
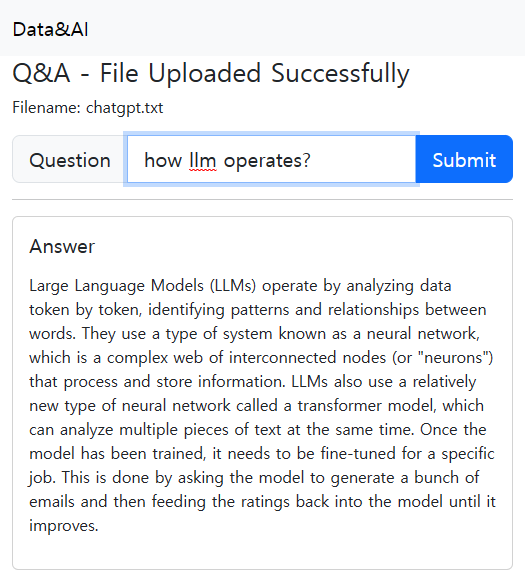
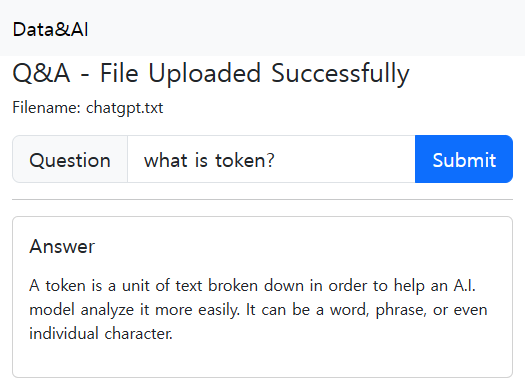
간단하게 만들어본 서비스이지만, 나만의 데이터를 활용해서 openAI를 활용할수 있다는 점에서 여러 프로세스에서 적용가능하겠다는 생각이 들었습니다.
반응형'AI&ML' 카테고리의 다른 글
구글Bard가 챗GPT보다 더 나은데? 구글의 반격 (0) 2023.05.11 Azure Cognitive Search (애저 인지 검색) (0) 2023.05.04 챗GPT 생성AI의 시대 - 기본개념 이해하기 (0) 2023.04.15 Azure AI Form Recognizer를 활용한 영어단어장 만들기 (0) 2023.02.09 Github Actions을 이용한 간단한 Docker 빌드/배포 자동화 (0) 2023.02.07